Today, the Alphaville section of the Financial Times published The invisible run-off, in which I discuss a new source of “quantitative tightening” that almost no one seems to have noticed. I estimate that $350 billion of private funds will be absorbed when the U.S. Treasury refinances its securities that are now in special accounts for state and local government bonds. The Treasuries are currently held in escrows to secure municipal bonds that have been “advance refunded.” An advance refunding is a complex refinancing technique for bonds that are months or years away from their first scheduled call date.
The Tax Cuts and Jobs Act prohibits advance refundings going forward because they increase the supply of tax-exempt bonds (at least until the old bonds are called), thereby shaving the revenue to the Treasury.
According to the Joint Committee on Taxation, the end of advance refundings will save the federal government $17 billion over the next ten years:

Of course, that’s not much in comparison to the overall projected effect of tax reform:

Over the next few years, perhaps $350 billion in escrow Treasuries will mature. These will have to be refinanced without the help of new advance refundings. The run-off from escrows is not as large as the Fed’s expected balance sheet reduction (as much an obsession to the markets as a sizzling steak to a dog), but the escrow wind-down could match about a third of the Fed’s roughly $1 trillion planned disposal of Treasuries. The loss of escrow funding to the Treasury, and the additional supply to the market, could be prove significant.
Addendum:
The key to the $350 billion estimate for escrow securities was the S&P Municipal Bond Prerefunded/ETM Index. The index includes about $190 billion in bonds that have been escrowed to a call date (“ETC”) or to escrowed to maturity (“ETM”). I scaled up the prerefunded bonds by taking the ratio of the whole S&P municipal bond universe ($2.2 trillion) to the full reported size of the municipal market ($3.8 trillion).
I was interested to see that the average coupon of the prerefunded bonds in the index is 4.9%. This seems to confirm the prevalence of 5% coupons in recent years. These high coupons (their yield is now 1.6%) were among the most attractive candidates for refunding.
The escrow Treasuries generally have much lower coupons than the refunded bonds they support, so more than $1 in Treasuries are needed to cover the interest payments on each $1 of refunded bonds. This relationship implies that $350 billion could be a conservative estimate for Treasuries in advance refunding escrows. On the other hand, some of the escrows are so short that they are considered to be “current refundings” instead of advance refundings. Current refundings are still allowed, but their short shelf life has probably limited their impact on the index. To the extent that some bonds in the index correspond to current refundings, the $350 billion estimate could be on the high side. Another distortion would be if the prerefunded share of the S&P index universe does not match that of the whole market.
Addendum added January 21, 2018






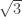 .
. of the “radius” from a corner of the outer cross to the center, so the construction generates an inner cross with the required radius,
of the “radius” from a corner of the outer cross to the center, so the construction generates an inner cross with the required radius,  as long as the original radius.
as long as the original radius.
 . Note that if the area shrinks by one-third, the width of the cross must scale down by the square root of 3. So every two steps the width shrinks by one-third, placing a little cross precisely inside the middle square of a larger cross.
. Note that if the area shrinks by one-third, the width of the cross must scale down by the square root of 3. So every two steps the width shrinks by one-third, placing a little cross precisely inside the middle square of a larger cross.